第一章 集合函数
Ancestors
返回指定成员在指定级别上的所有祖先的集合。
语法
ANCESTORS(member, level)
示例
select
Ancestors([组织].[XYZ集团].[北京总部].[研发中心].[开发1部],[组织].[LEVEL1]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([期间].&[50652],[场景].&[50685],[产品].&[50688],[科目].&[50253])
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年10月
科目: 物业外包
-----------------------------------------------------------------------------------------------------------------
组织维度成员[开发1部]层级为0,他层级为1的祖先为[研发中心]。
BottomCount
返回指定集合中指定数目具有较小值的组合组成的集合
语法
BOTTOMCOUNT( set , index [ ,numeric_value ] )
参数
set
返回集的有效多维表达式 (MDX)。
index
是返回组合的数目(即单元格的数目)。
numeric_value
(可选)如果指定了numeric_value,此函数将根据numeric_value计算在集合上的值,并按升序对组合进行排序。
示例一
select
BottomCount({[期间].[2023年].[2023年2季度].Children},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50584],[场景].&[50685],[产品].&[50688],[科目].&[50220])
运行结果:
产品: 不分
场景: 累计预算
科目: 办公费
组织: 开发1部
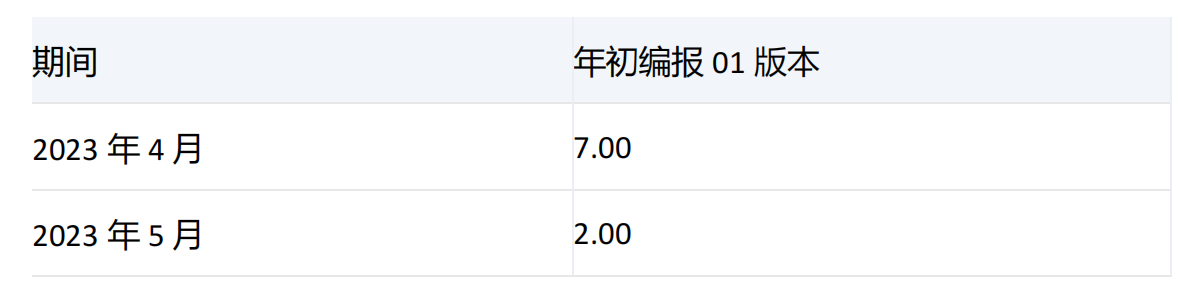
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年2季度]的子项有3个分别为[2023年4月]、[2023年5月]、[2023年6月],对应的[办公费]值分别为7、2、1,由于index值为2且没有指定numeric_value,所以顺序返回[2023年4月]和[2023年5月]。
示例二
select
BottomCount({[期间].&[50643].Children},2,[科目].&[50220]) on rows,
{[科目].&[50220]} on columns
from [模型一]
where ([组织].&[50584],[场景].&[50685],[产品].&[50688],[版本].&[50672])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
组织: 开发1部

-----------------------------------------------------------------------------------------------------------------
期间维度[2023年2季度]的子项有3个分别为[2023年4月]、[2023年5月]、[2023年6月],对应的[办公费]值分别为7、2、1,由于指定了numeric_value参数,所以要先对7、2、1进行升序排列,结果为1、2、7,并且index的值为2,所以会取升序排列后前两个的值,返回对应的[2023年6月]和[2023年5月]。
BottomPercent
将指定维度成员范围内数据升序排列,从最小值开始累加,当累加大于或等于范围总和的指定百分比后,返回集合,再结合数值函数,将集合中的值写到单元格中。
语法
BOTTOMPERCENT( set , percentage ,numeric_value )
参数
Percentage
是返回的单元格的值占set指定的所有单元格值的和的最小比例
numeric_value
根据numeric_value计算在集合上的值,并按升序对指定集合中的组合进行排序
备注
百分比不需要输入%
示例
select
BottomPercent({[科目].&[50220]}*{[期间].[2023年].[2023年2季度].Children},30,[组织].&[50584])on rows,
{[组织].&[50584]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
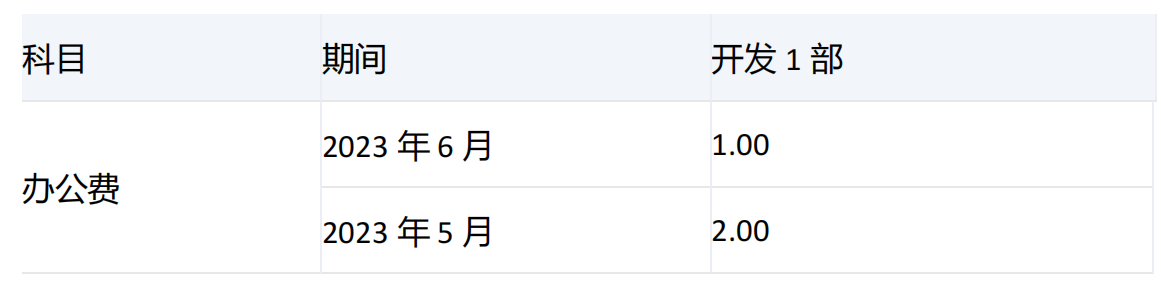
-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年2季度]的子项[2023年4月]、[2023年5月]、[2023年6月]的[科目].&[50220]值分别为7、2、1,按升序从1、2、7里面取,指定百分比为30,也就是1、2、7先求和再乘以30%为3,当取到2时,1+2刚好等于3,满足大于等于3的条件,所以返回对应的[2023年6月]和[2023年5月]。
BottomSum
将指定维度成员范围内数据升序排列,从最小值开始累加,当累加大于或等于给定的值后,返回集合。
语法
BOTTOMSUM( set, value, numeric_value)
参数
set
返回集的有效多维表达式 (MDX)。
Value
指定值value
Numeric_value
返回集的排序依据,优先级高于Set_Expression。
备注
根据numeric_value计算在集合上的值,按升序排列之后,返回较小值的一组元组,其累加和等于或者刚超过指定值value。
示例一
select
BottomSum({[科目].&[50236]}*{[期间].[2023年].[2023年1季度].Children},2,[组织].&[50582])on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本

-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年1季度]的子项[2023年1月]、[2023年2月]、[2023年3月]的[研究开发费]值分别为2、0、24,在BottomSum函数的集合中,期间维度位置靠后,所以会对[研究开发费]的[2023年3季度]的子项的值进行升序排列,顺序为0、2、24,对应返回的期间顺序为[2023年2月]、[2023年1月]、[2023年3月];根据numeric_value计算在集合上的值,按升序排列之后,返回较小值的一组元组,其累加和等于或大于指定值value=2,所有返回集合为0、2,对应返回的期间顺序为[2023年2月]、[2023年1月]。
Children
返回指定成员的子代集合
语法
member.Children
示例
select
[期间].[2023年].[2023年3季度].Children on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([科目].&[50236],[场景].&[50685],[产品].&[50688],[版本].&[50672])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
科目: 研究开发费
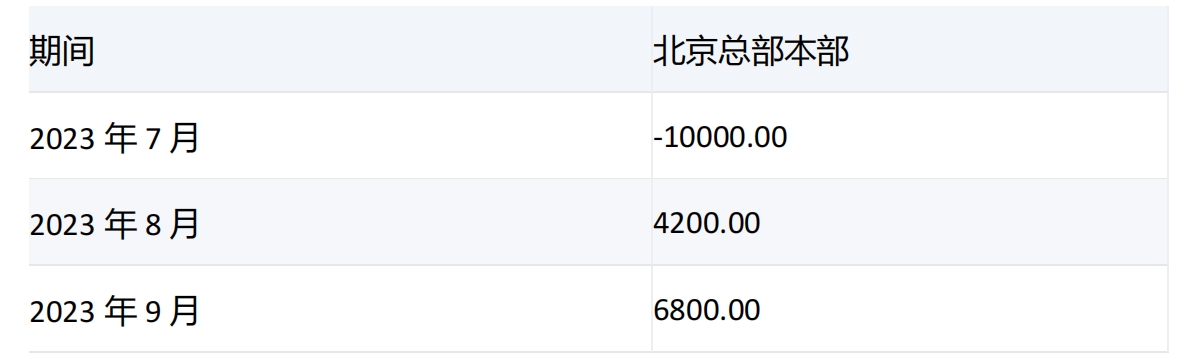
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年3季度]的子带有[2023年7月]、[2023年8月]、[2023年9月]三个月份.
CrossJoin
语法
CROSSJOIN(set, set, ……..)
set * set……
参数
set
返回集的有效多维表达式 (MDX),至少要有两个。
备注
返回一个或多个集合的外积,例如,当第一个集合包含{x1, x2,…,xn},第二个集合由{y1, y2,…, yn},这些集合的外积是
{(x1, y1), (x1, y2),...,(x1, yn), (x2, y1), (x2, y2),...,
(x2, yn),..., (xn, y1), (xn, y2),..., (xn, yn)}
示例
select
CrossJoin({[科目].&[50236],[科目].&[50231]},{[期间].&[50640],[期间].&[50641],[期间].&[50642]})on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
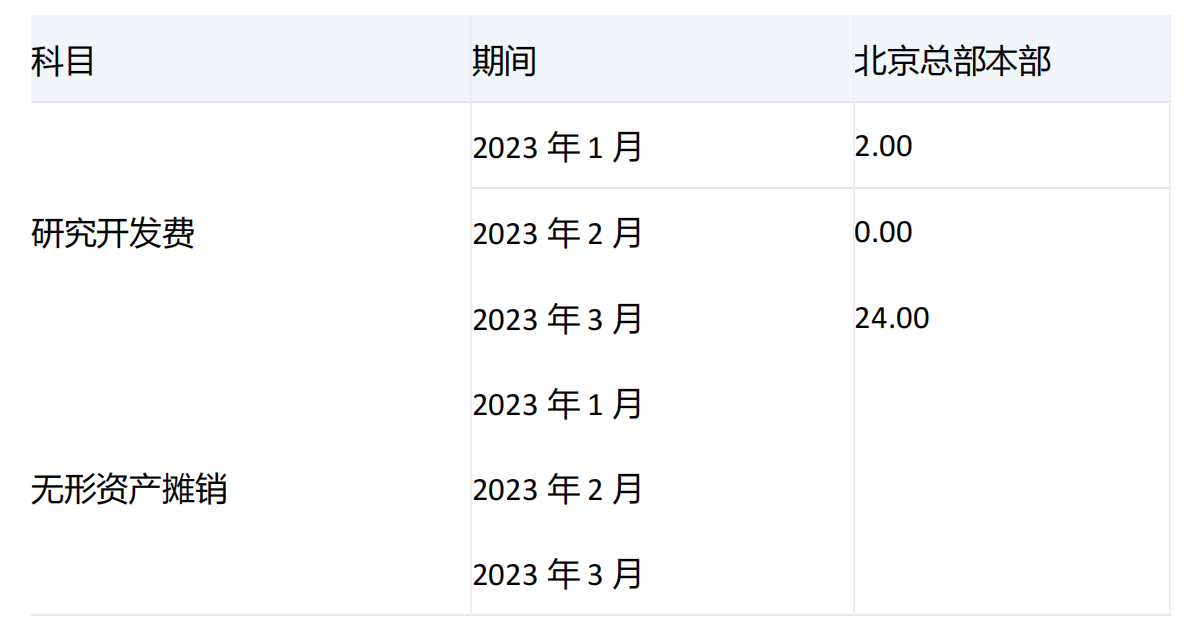
-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年1月]、[2023年2月]、[2023年3月]的[研究开发费]值分别为2、0、24,[无形资产摊销]值为null;在CROSSJOIN中返回这几个集合的外积,分别为2、0、24.
Descendants
返回成员在指定级别上的后代集合,可以选择包括或不包括其他级别上的后代。
语法
DESCENDANTS(member, level [, desc_flags] )
参数
desc_flags用于指定后代集合的类别
Desc_flags类别

示例一
select
Descendants([科目].&[50187],[科目].[LEVEL0],SELF) on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[期间].[2023年].[2023年3季度].[2023年7月])
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年7月
版本: 年初编报01版本
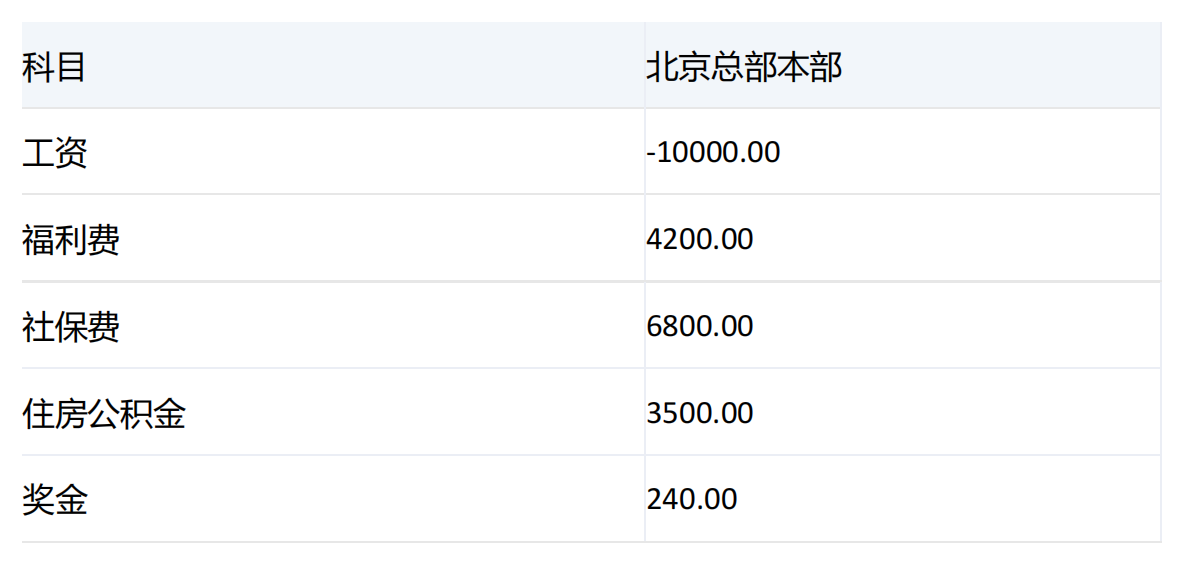
-----------------------------------------------------------------------------------------------------------------
行上成员是【科目】维度key为[50187]的成员的后代中级别为0的成员
示例二
select
Descendants([科目].&[50187],[科目].[LEVEL0]) on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[期间].[2023年].[2023年3季度].[2023年7月])
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年7月
版本: 年初编报01版本
-----------------------------------------------------------------------------------------------------------------
结果与示例1相同
Distinct
计算指定集合,从集合中移除重复元组,并返回结果集。
语法
DISTINCT(set)
参数
set
返回集的有效多维表达式 (MDX)。
示例
select
Distinct({[期间].&[50640],[期间].&[50641],[期间].&[50642],[期间].&[50642],[期间].&[50642]})on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
科目:研究开发费
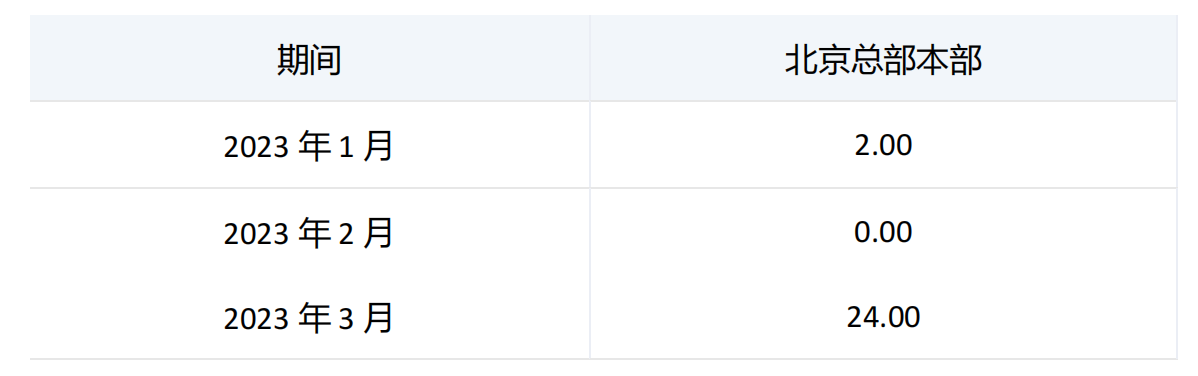
-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年1月]、[2023年2月]、[2023年3月]的[研究开发费]值分别为2、0、24,期间维度[2023年3月]重复了3次,在DISTINCT函数计算该集合时,从集合中移除重复元组[2023年3月],并返回结果集,分别为2、0、24.
DrilldownLevel
将某个集的成员深化到该集中所表示的最低级别的下一个级别。
指定向下钻取的级别是可选的,但如果设置了级别,则可以使用 级别表达式 或 索引级别。 这两种参数互相排斥。 最后,如果计算成员出现在查询中,你可指定一个聚合以将这些成员包含在行集中。
语法
DRILLDOWNLEVEL(set [ [,level] | [,,index] ])
参数
set
返回集的有效多维表达式 (MDX)。
level
(可选)显式标识维度上要钻取层级的 MDX 表达式。
Index
(可选)有效的数值表达式,它指定要钻取的维度在集合中从左往右的顺序编号,从0开始。
备注
leveL和index不可同时存在。
当level和index未指定,或者参数无效时,默认对集合中第一个维度层级小的成员进行下钻。
示例一
select
DrilldownLevel({[期间].[2023年].[2023年1季度],[期间].[2023年]},[期间].[LEVEL2]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
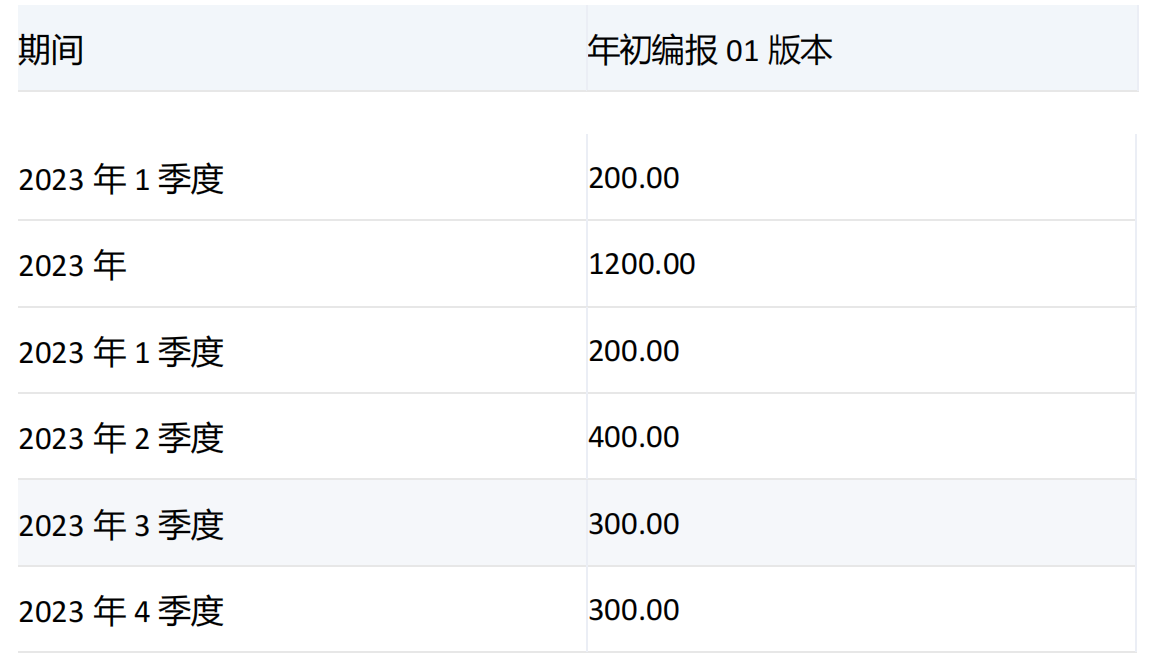
-----------------------------------------------------------------------------------------------------------------
由于集合中期间维度[期间].[2023年]的层级为2,符合第二个参数的层级[期间].[LEVEL2],所以对[期间].[2023年]进行下钻,返回[2023年]和它的子项[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度]。
而[期间].[2023年].[2023年1季度]的层级为1,不符合第二个参数的层级[期间].[LEVEL2],所以不进行下钻。
示例二
select
DrilldownLevel({[科目].&[50215]}*{[期间].[2023年].[2023年1季度],[期间].[2023年]},,1) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合中第一个维度为[科目],第二个维度为[期间],由于Index为1(从0开始),所以对[期间]维度进行下钻,而[期间].[2023年].[2023年1季度]层级为1,[期间].[2023年]层级为2,优先对层级低的成员进行下钻,所以对[2023年].[2023年1季度]进行下钻,返回[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]。
示例三
select
DrilldownLevel({[期间].[2023年].[2023年1季度],[期间].[2023年]}*{[科目].&[50215]}) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
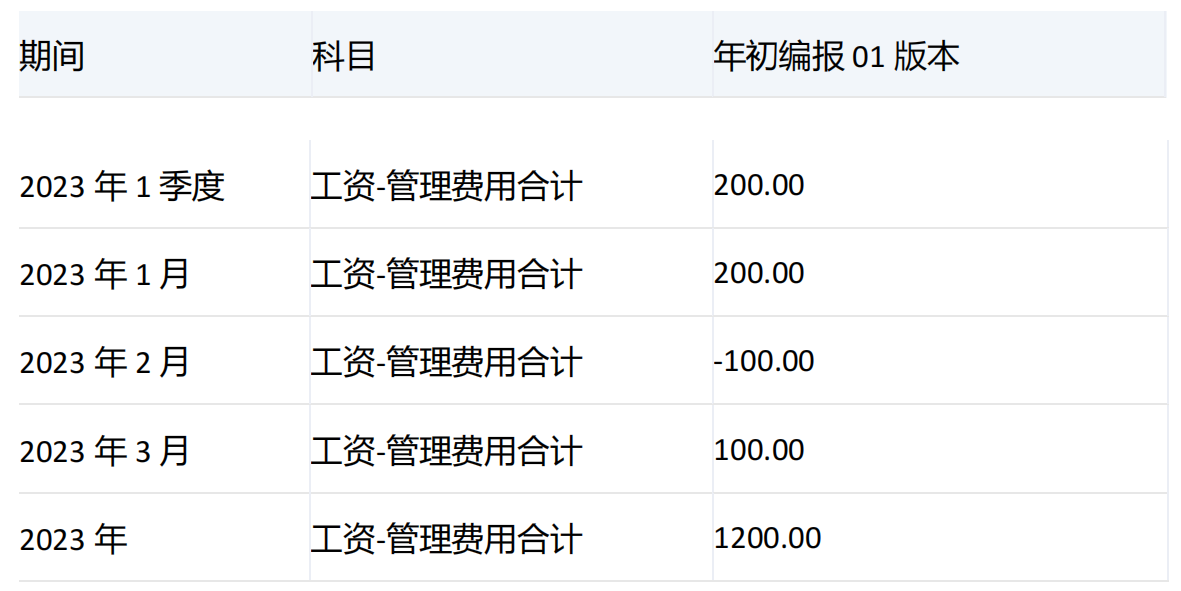
-----------------------------------------------------------------------------------------------------------------
集合中第一个维度为[期间],第二个维度为[科目],由于未指定参数,所以对第一个维度[期间]维度进行下钻,而[期间].[2023年].[2023年1季度]层级为1,[期间].[2023年]层级为2,优先对层级小的成员进行下钻,所以对[2023年].[2023年1季度]进行下钻,返回[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]。
DrilldownLevelBottom
默认对集合中第一个维度下级别最低维度成员进行下钻,返回下钻后的前几个成员组成的集合。如果指定了level,则对集合中指定维度下指定层级维度成员进行下钻。如果指定了numeric_value,则优先对下钻出的成员进行升序排列,再返回前几个成员。
语法
DRILLDOWNLEVELBOTTOM(set, count [, [level] , numeric_value ] )
参数
set
返回集的有效多维表达式 (MDX)。
count
限制钻取的tuple数目(不能超过count值)。
level
(可选)不指定level则下钻set中第一个维度的最低级别的成员;level指定了,筛选出set中该级别上的成员做下钻操作。
numeric_value
不指定则直接按照层次结构的顺序取最多count个子代成员;
如果指定了,钻取的子代成员先排序(升序),再从小到大取最多count个子代成员;
示例一
select
DrilldownLevelBottom({[期间].[2023年].[2023年1季度],[期间].[2023年]}*{[科目].&[50215]},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于未指定level,默认对set中第一个维度[期间]进行下钻,[2023年1季度]的级别为1,[2023年]的级别为2,由于[2023年1季度]的级别小,所以会对[2023年1季度]进行下钻。
未指定numeric_value,默认按原维度成员顺序排列。由于count为2,所以只返回[2023年1月]和[2023年2月]。
示例二
select
DrilldownLevelBottom({[期间].[2023年].[2023年1季度],[期间].[2023年]}*{[科目].&[50215]},2,,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
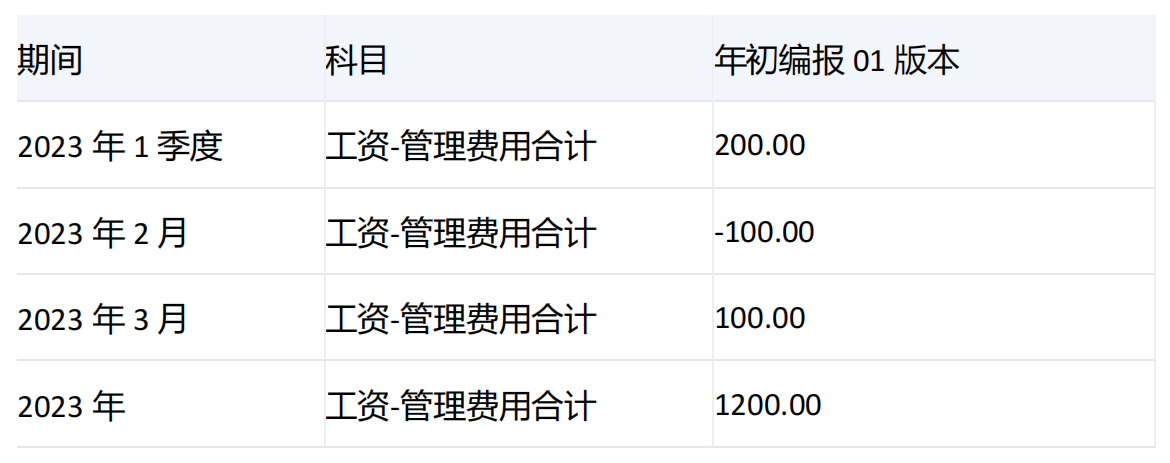
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于未指定level,默认对set中第一个维度[期间]进行下钻,[2023年1季度]的级别为1,[2023年]的级别为2,由于[2023年1季度]的级别小,所以会对[2023年1季度]进行下钻。
由于指定了numeric_value,会将[2023年1月]、[2023年2月]、[2023年3月]的值按照升序排列,-100、100、200。由于count为2,所以只取数值升序排列后前两个对应的维度分别是[2023年2月]和[2023年3月]。
示例三
select
DrilldownLevelBottom({[科目].&[50215]}*{[期间].[2023年].[2023年1季度],[期间].[2023年]},2,[期间].[LEVEL1],[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
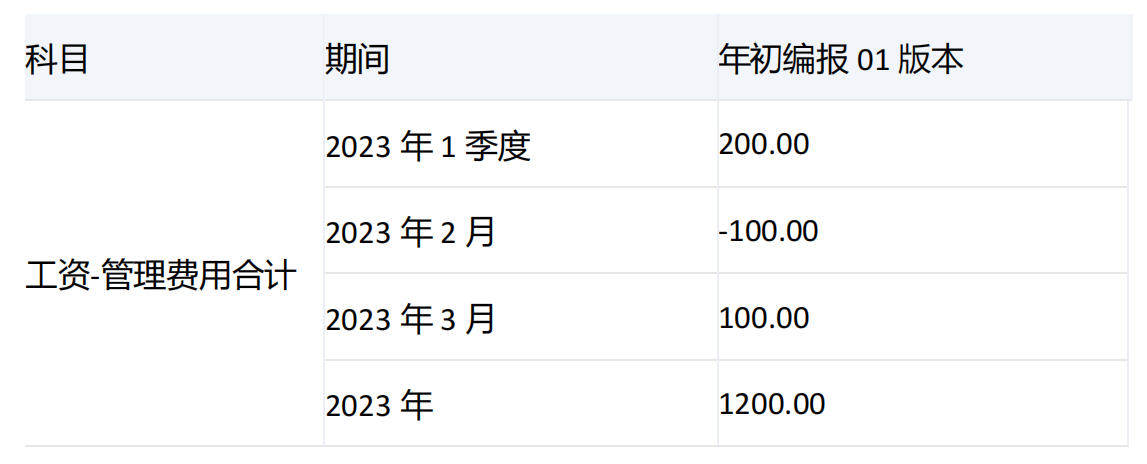
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于指定了level,[期间].[LEVEL1],而集合中[2023年1季度]的级别为1,所以会对[2023年1季度]进行下钻。
由于指定了numeric_value,会将[2023年1月]、[2023年2月]、[2023年3月]的值按照升序排列,-100、100、200。由于count为2,所以只取数值升序排列后前两个对应的维度分别是[2023年2月]和[2023年3月]。
DrillDownLevelTop
默认对集合中第一个维度下级别最低维度成员进行下钻,返回下钻后的前几个成员组成的集合。如果指定了level,则对集合中指定维度下指定层级维度成员进行下钻。如果指定了numeric_value,则优先对下钻出的成员进行降序排列,再返回前几个成员。
语法
DRILLDOWNLEVELTOP(set, count [, [level] , numeric_value ] )
参数
set
返回集的有效多维表达式 (MDX)。
count
限制钻取的tuple数目(不能超过count值)。
level
不指定level则下钻第一个维度的最低级别的成员;
指定了,筛选出set中该级别上的成员做下钻操作。
numeric_value
不指定则直接按照层次结构的顺序取最多count个子代成员;
如果指定了,钻取的同级成员先排序(降序),再从大到小取最多count个子代成员;
示例一
select
DrilldownLevelTop({[期间].[2023年].[2023年1季度],[期间].[2023年]}*{[科目].&[50215]},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
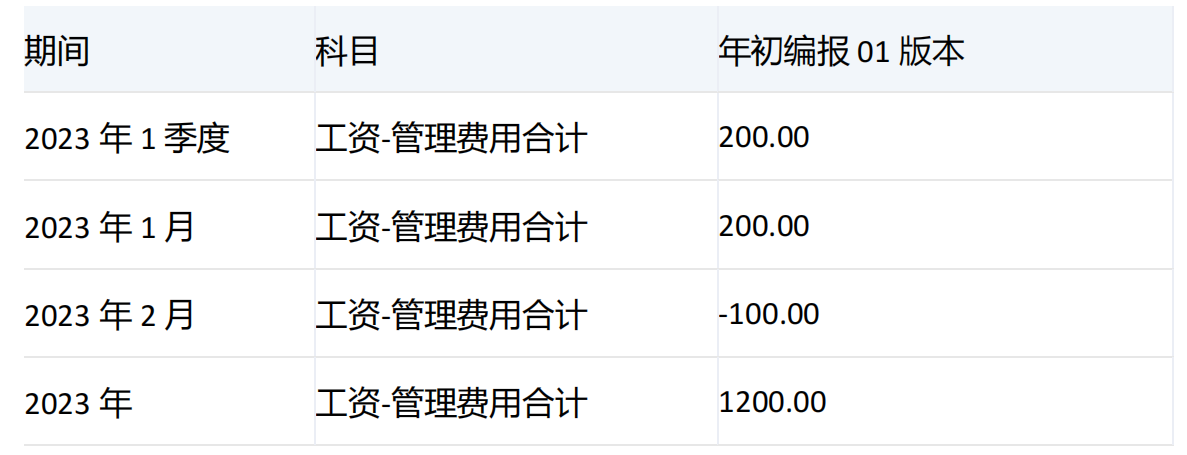
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于未指定level,默认对set中第一个维度[期间]进行下钻,[2023年1季度]的级别为1,[2023年]的级别为2,由于[2023年1季度]的级别小,所以会对[2023年1季度]进行下钻。
未指定numeric_value,默认按原维度成员顺序排列。由于count为2,所以只返回[2023年1月]和[2023年2月]。
示例二
select
DrilldownLevelTop({[期间].[2023年].[2023年1季度],[期间].[2023年]}*{[科目].&[50215]},2,,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
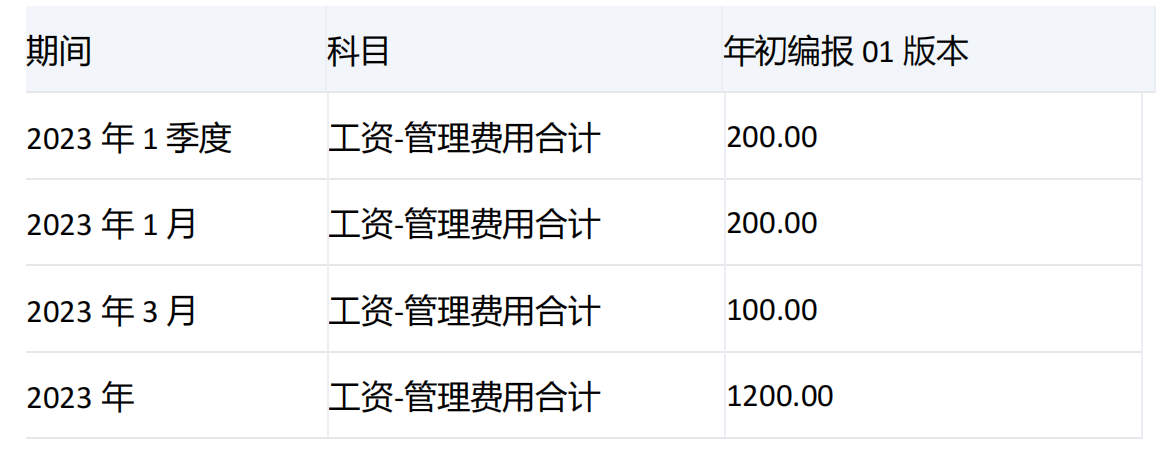
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于未指定level,默认对set中第一个维度[期间]进行下钻,[2023年1季度]的级别为1,[2023年]的级别为2,由于[2023年1季度]的级别小,所以会对[2023年1季度]进行下钻。
由于指定了numeric_value,会将[2023年1月]、[2023年2月]、[2023年3月]的值按照降序排列,200、100、-100。由于count为2,所以只取数值升序排列后前两个对应的维度分别是[2023年1月]和[2023年3月]。
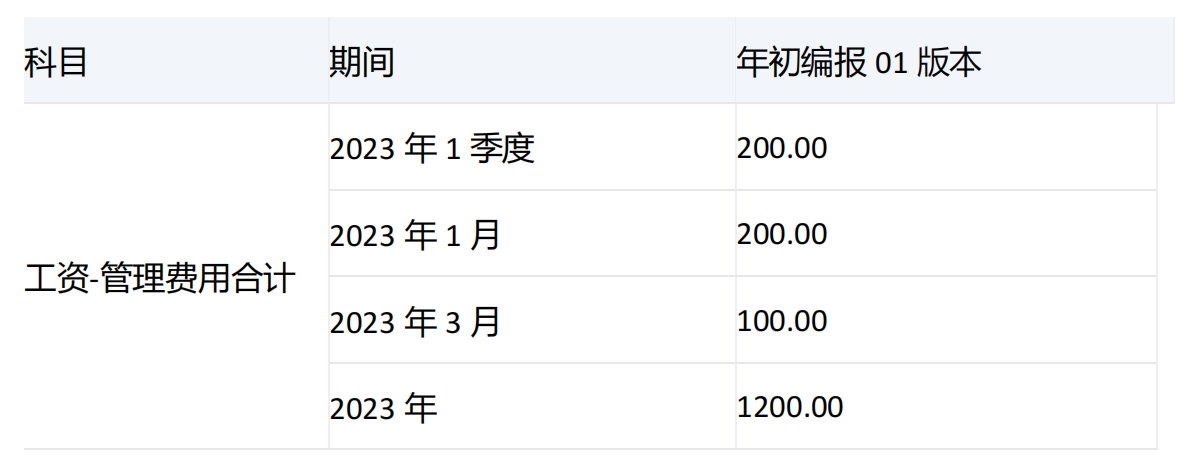
示例三
select
DrilldownLevelTop({[科目].&[50215]}*{[期间].[2023年].[2023年1季度],[期间].[2023年]},2,[期间].[LEVEL1],[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年1季度]和它的子项[2023年1月]、[2023年2月]、[2023年3月]的[工资-管理费用合计]值分别为200、200、-100、100,由于指定了level,[期间].[LEVEL1],而集合中[2023年1季度]的级别为1,所以会对[2023年1季度]进行下钻。
由于指定了numeric_value,会将[2023年1月]、[2023年2月]、[2023年3月]的值按照降序排列,200、100、-100。由于count为2,所以只取数值升序排列后前两个对应的维度分别是[2023年1月]和[2023年3月]。
DrillDownMember
遍历集合1中的成员,如果也存在于集合2中则做该成员的下钻。结果集包含集合1中的成员和下钻得到的成员。
语法
DRILLDOWNMEMBER(set, set [, RECURSIVE] )
参数
set
返回集的有效多维表达式 (MDX)。
recursive
(可选)指定了recursive,则递归地将结果集中的成员与第二个集合进行比较,判断是否继续下钻
备注
如果第一个集合包含父成员和一个或者多个子成员,则父成员不会下钻;
第二个集合的维度只能有一个;
示例一
select
DrilldownMember({[期间].[2023年]},{[期间].[2023年]}) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,结果集中返回[2023年]和他的子项。
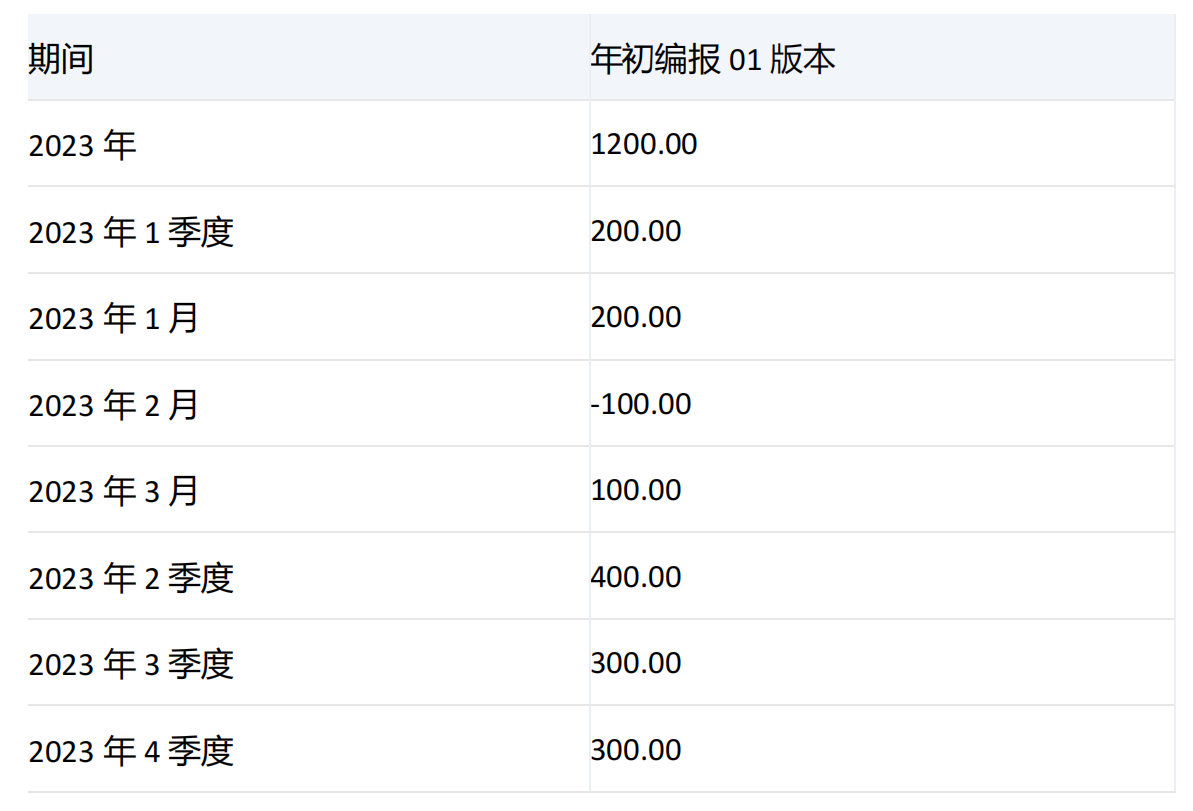
示例二
select
DrilldownMember({[期间].[2023年]},{[期间].[2023年],[期间].[2023年].[2023年1季度]},recursive) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,结果集中返回[2023年]和他的子项。由于有recursive参数,且集合2中有[2023年]的子项[2023年1季度],所以对[2023年1季度]进行下钻,结果集中返回[2023年1季度]的子项。
DrillDownMemberBottom
遍历集合1中的成员,如果也存在于集合2中则做该成员的下钻。结果集包含集合1中的成员和下钻得到的成员,默认顺序排列。若指定了numeric_value
参数,则下钻得到的成员按值进行升序排列,再返回不大于count个数成员。若指定了recursive参数,并且集合2中存在集合1第一次钻取的子项,则对该子项进行下钻,返回的子项同时受recursive和count参数影响,效果同上。
语法
DRILLDOWNMEMBERBOTTOM(set, set, count [, [numeric_value] [, RECURSIVE] ] )
参数
set
返回集的有效多维表达式 (MDX)。
count
限制下钻的tuple的数目(不超过count值)
numeric_value
(可选)指定了numeric_value则下钻的同级成员会据此排序(升序)
recursive
(可选)指定了recursive,则递归地将结果集中的成员与第二个集合进行比较,判断是否继续下钻
备注
如果第一个集合包含父成员和一个或者多个子成员,则父成员不会下钻;
第二个集合的维度只能有一个;
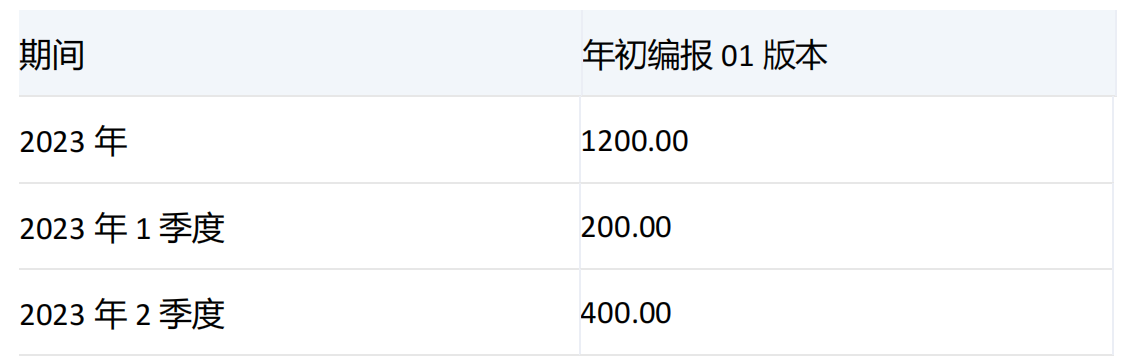
示例一
select
DrilldownMemberBottom({[期间].[2023年]},{[期间].[2023年]},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,根据count的值,结果集中返回[2023年]和他的前两个子项[2023年1季度]和[2023年2季度]。
示例二
select
DrilldownMemberBottom({[期间].[2023年]},{[期间].[2023年]},2,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],对应的值分别为200、400、300、300。由于指定了numeric_value参数,所以将[2023年]的子项的值按照升序排列,结果为200、300、300、400。根据count的值,结果集中返回[2023年]和他子项中升序排列的前两项分别为[2023年1季度]和[2023年4季度]。
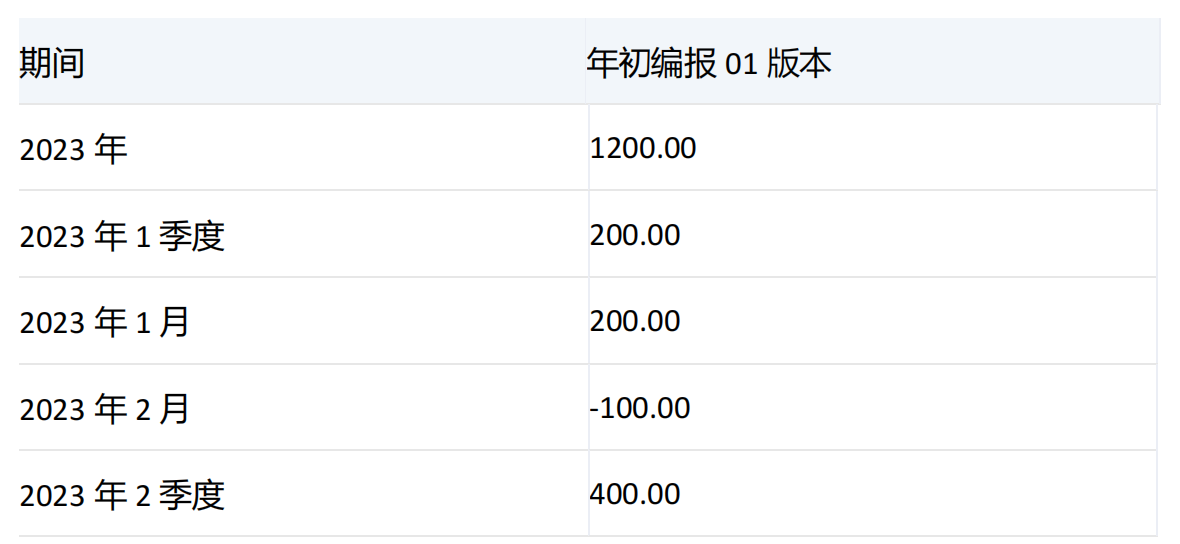
示例三
select
DrilldownMemberBottom({[期间].[2023年]},{[期间].[2023年],[期间].[2023年].[2023年1季度]},2,,recursive) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],由于指定了recursive参数,且集合2中有[2023年1季度],所以对[2023年1季度]下钻,[2023年1季度]的子项有[2023年1月]、[2023年2月]、[2023年3月]。根据count的值,结果集中返回[2023年]和他子项中前两项分别为[2023年1季度]和[2023年2季度]还有[2023年1季度]子项中的前两项[2023年1月]和[2023年2月]。
示例四
select
DrilldownMemberBottom({[期间].[2023年]},{[期间].[2023年],[期间].[2023年].[2023年1季度]},2,[版本].&[50672],recursive) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
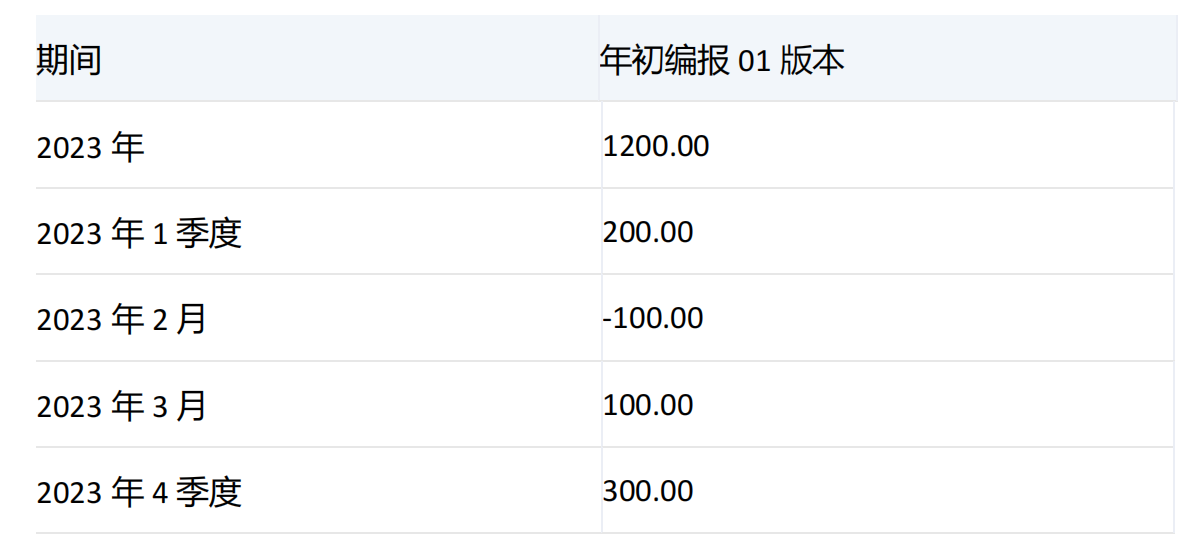
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],对应的值分别为200、400、300、300。由于指定了numeric_value参数,所以将[2023年]的子项的值按照升序排列,结果为200、300、300、400。根据count的值,结果集中返回[2023年]和他子项中升序排列的前两项分别为[2023年1季度]和[2023年4季度]。
由于指定了recursive参数,且[2023年1季度]也在集合2中,所以对[2023年1季度]进行下钻,[2023年1季度]的子项有[2023年1月]、[2023年2月]、[2023年3月],对应的值分别为200、-100、100,升序排列后为-100、100、200,根据count的值,结果集中返回[2023年1季度]和他子项中升序排列的前两项分别为[2023年2月]和[2023年3月]。
DrillDownMemberTop
遍历集合1中的成员,如果也存在于集合2中则做该成员的下钻。结果集包含集合1中的成员和下钻得到的成员,默认顺序排列。若指定了numeric_value
参数,则下钻得到的成员按值进行降序排列,再返回不大于count个数成员。若指定了recursive参数,并且集合2中存在集合1第一次钻取的子项,则对该子项进行下钻,返回的子项同时受recursive和count参数影响,效果同上。
语法
DRILLDOWNMEMBERTOP(set, set, count [, [numeric_value] [, RECURSIVE] ] )
参数
set
返回集的有效多维表达式 (MDX)。
count
限制下钻的tuple的数目(不超过count值)
numeric_value
(可选)指定了numeric_value则下钻的同级成员会据此排序(降序)
recursive
(可选)指定了recursive,则递归地将结果集中的成员与第二个集合进行比较,判断是否继续下钻
备注
如果第一个集合包含父成员和一个或者多个子成员,则父成员不会下钻;
第二个集合的维度只能有一个;
示例一
select
DrilldownMemberTop({[期间].[2023年]},{[期间].[2023年]},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
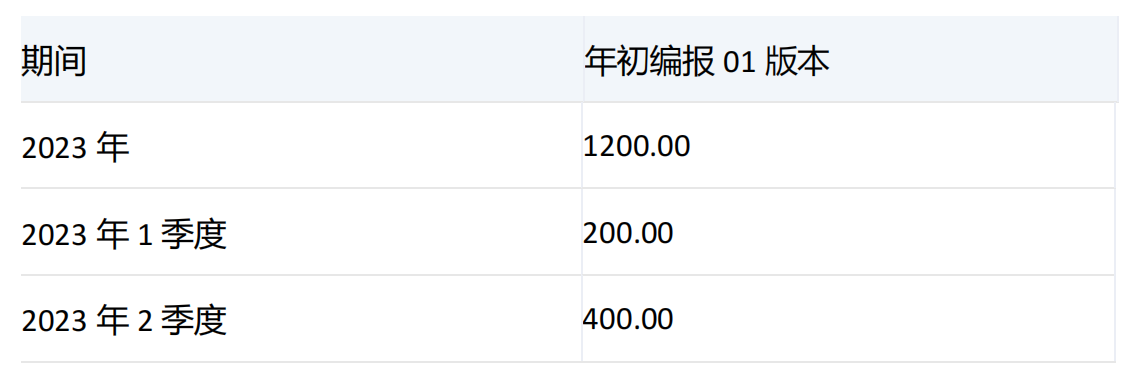
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,根据count的值,结果集中返回[2023年]和他的前两个子项[2023年1季度]和[2023年2季度]。
示例二
select
DrilldownMemberTop({[期间].[2023年]},{[期间].[2023年]},2,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
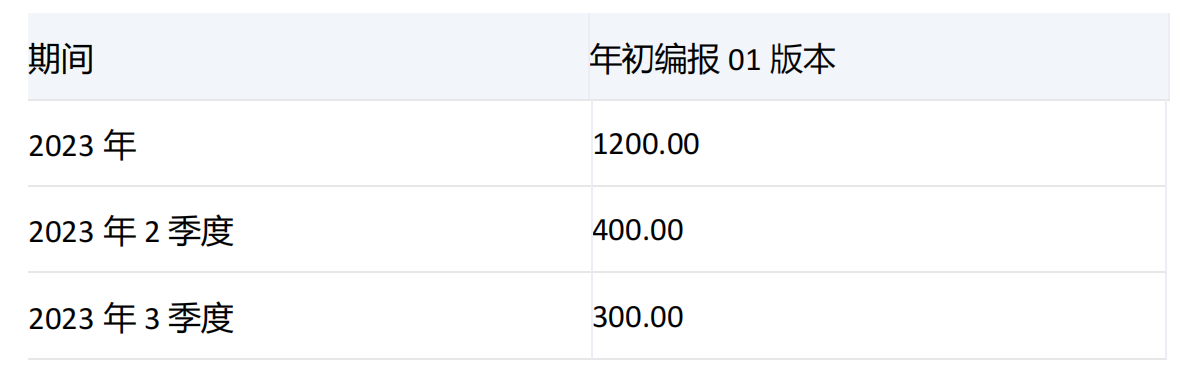
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],对应的值分别为200、400、300、300。由于指定了numeric_value参数,所以将[2023年]的子项的值按照降序排列,结果为400、300、300、200。根据count的值,结果集中返回[2023年]和他子项中降序排列的前两项分别为[2023年2季度]和[2023年3季度]。
示例三
select
DrilldownMemberTop({[期间].[2023年]},{[期间].[2023年],[期间].[2023年].[2023年1季度]},2,,recursive) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],由于指定了recursive参数,且集合2中有[2023年1季度],所以对[2023年1季度]下钻,[2023年1季度]的子项有[2023年1月]、[2023年2月]、[2023年3月]。根据count的值,结果集中返回[2023年]和他子项中前两项分别为[2023年1季度]和[2023年2季度]还有[2023年1季度]子项中的前两项[2023年1月]和[2023年2月]。
示例四
select
DrilldownMemberTop({[期间].[2023年]},{[期间].[2023年],[期间].[2023年].[2023年2季度]},2,[版本].&[50672],recursive) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
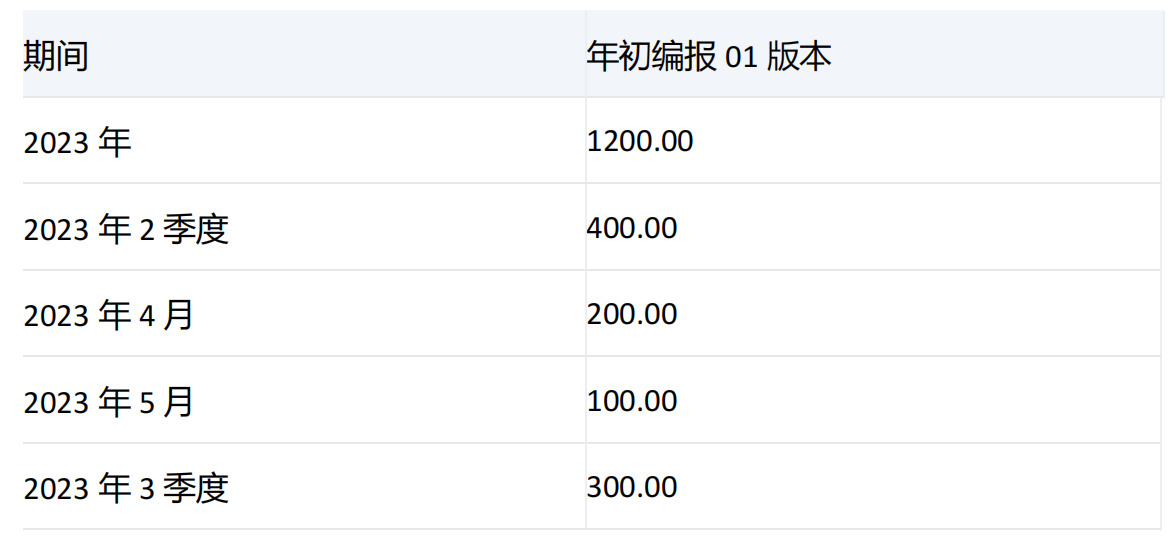
集合1和集合2中均有期间维度[2023年],并且集合1中没有[2023年]的子项,所以对[2023年]进行下钻,[2023年]的子项有[2023年1季度]、[2023年2季度]、[2023年3季度]、[2023年4季度],对应的值分别为200、400、300、300。由于指定了numeric_value参数,所以将[2023年]的子项的值按照降序排列,结果为400、300、300、200。根据count的值,结果集中返回[2023年]和他子项中降序排列的前两项分别为[2023年2季度]和[2023年3季度]。
由于指定了recursive参数,且[2023年2季度]也在集合2中,所以对[2023年2季度]进行下钻,[2023年2季度]的子项有[2023年4月]、[2023年5月]、[2023年6月],对应的值分别为200、100、100,降序排列后为200、100、200,根据count的值,结果集中返回[2023年2季度]和他子项中降序排列的前两项分别为[2023年4月]和[2023年5月]。
DrillupLevel
默认用集合中第一个维度中去除级别最低的维度成员来组成结果集。指定level后用不低于指定级别的成员组成结果集。
语法
DRILLUPLEVEL(set [, level])
参数
set
返回集的有效多维表达式 (MDX)。
level
(可选)指定了level,筛选集合中不低于指定级别的成员,如果没有指定level,则该函数通过检索比指定集合中引用的第一个维度的最低级别高的成员来构造集合。
示例一
select
DrillupLevel({[期间].[2023年].[2023年1季度],[期间].[2023年]}) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合中只有期间维度,[2023年1季度]的级别为1,[2023年]的级别为2,[2023年1季度]的级别最低,所以去掉[2023年1季度],返回[2023年]。
示例二
select
DrillupLevel({[期间].[2023年].[2023年1季度],[期间].[2023年]},[期间].[LEVEL0]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部

-----------------------------------------------------------------------------------------------------------------
集合中只有期间维度,[2023年1季度]的级别为1,[2023年]的级别为2,指定层级为[期间].[LEVEL0]而目前集合中的成员层级均大于0都满足条件,所以返回[2023年]和[2023年1季度]。
DrillupMember
遍历第一个集合的成员,如果是第二个集合中的成员,则删除集合一中紧跟着该成员的子代。
语法
DRILLUPMEMBER(set, set)
参数
set
返回集的有效多维表达式 (MDX)。
备注
第二个set只能包含一个维度
示例一
select
DrillupMember({[期间].[2023年],[期间].[2023年].[2023年1季度],[期间].[2023年].[2023年1季度].[2023年1月]},{[期间].[2023年].[2023年1季度]}) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50585],[场景].&[50685],[产品].&[50688],[科目].&[50215])
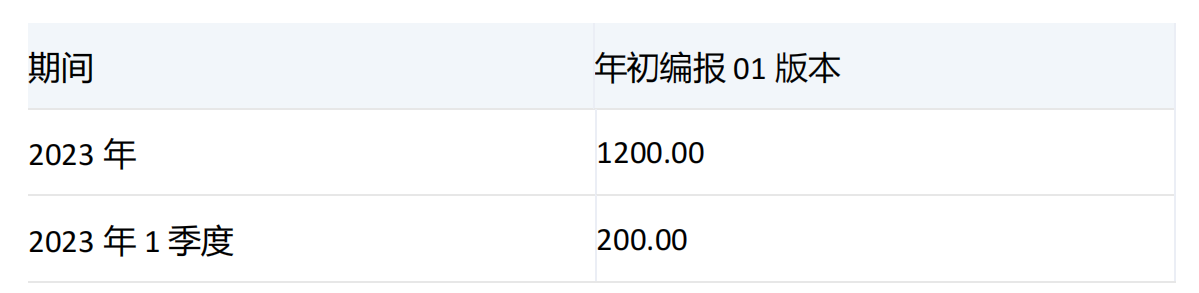
运行结果:
产品: 不分
场景: 累计预算
科目: 工资-管理费用合计
组织: 开发2部
-----------------------------------------------------------------------------------------------------------------
集合2中维度成员为[2023年1季度],集合1中[2023年1季度]后面为[2023年1月]刚好是前者的子项,所以被去掉,返回[2023年]和[2023年1季度]。
Except
遍历第一个集合,如果成员或者元组不存在于第二个集合,加入结果集,默认不保留集合中的重复项,可以选择加上ALL参数保留重复项。
语法
EXCEPT( set , set [, [ALL] ] )
参数
set
返回集的有效多维表达式 (MDX)。
ALL
(可选)如果写了参数,则保留重复项。
示例一
select
{Except({{[科目].&[50187].Children},{[科目].&[50188]}},{[科目].&[50189]})} on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[期间].&[2023年7月])
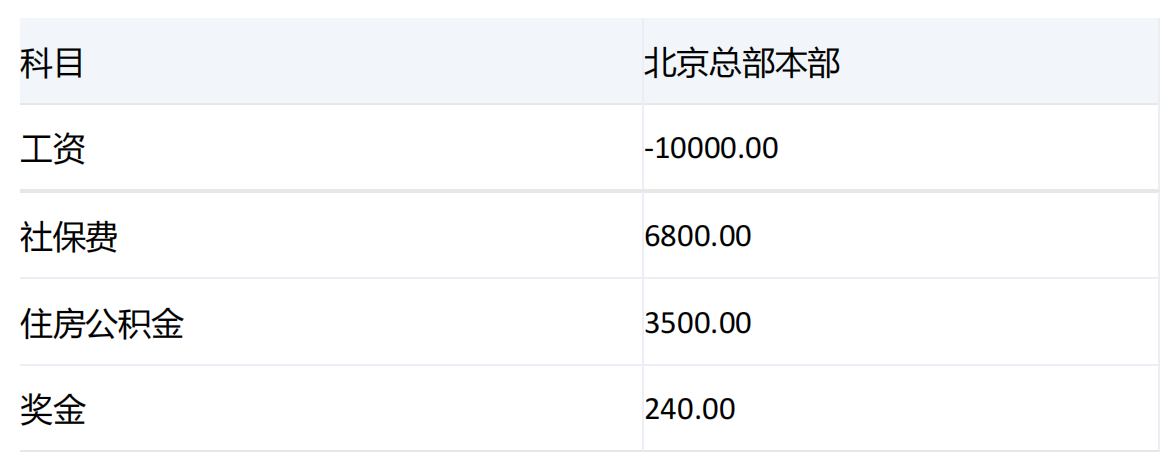
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年7月
版本: 年初编报01版本
-----------------------------------------------------------------------------------------------------------------
[科目]维度key为[50187]的成员的子项一共有5个,key分别为[50188],[50189],[50190],[50191],[50192]
结果集中去除了key为[50189]的成员,key为[50188]的重复项只保留了一个。
示例二
select
{Except({{[科目].&[50187].Children},{[科目].&[50188]}},{[科目].&[50189]},all)} on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[期间].&[2023年7月])
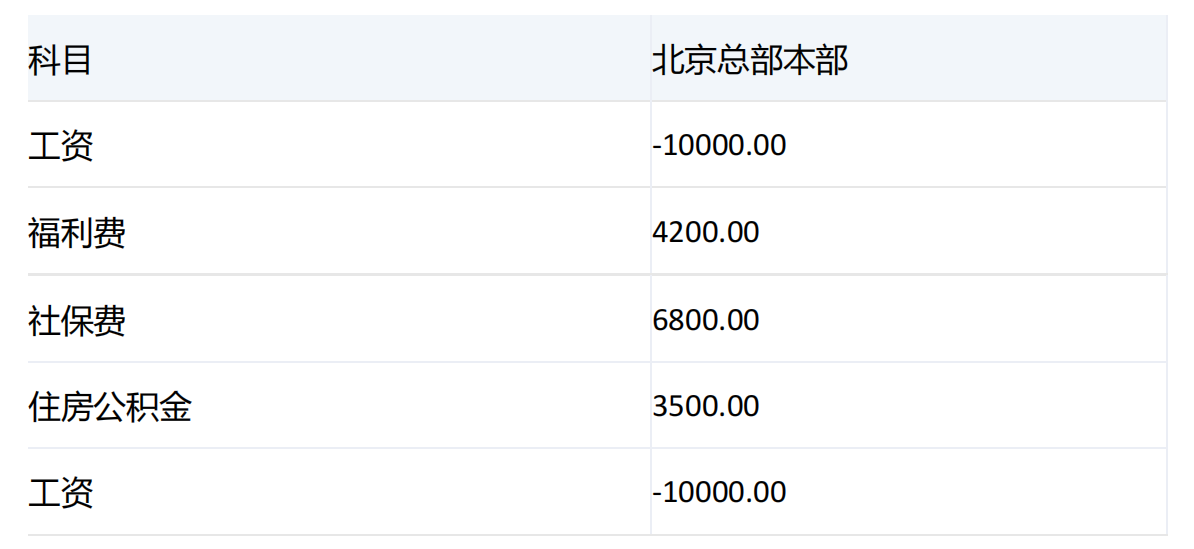
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年7月
版本: 年初编报01版本
-----------------------------------------------------------------------------------------------------------------
和示例1的结果相比,最后一行多了个重复项【工资】
Extract
查询粒度粗化
语法
EXTRACT(set, hier_name…)
参数
set
返回集的有效多维表达式 (MDX)。
hier_name
有1至多个,用逗号分隔
示例
select
{Extract(crossjoin({[科目].&[50187].Children},{[期间].&[50648]}),[科目])} on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672])
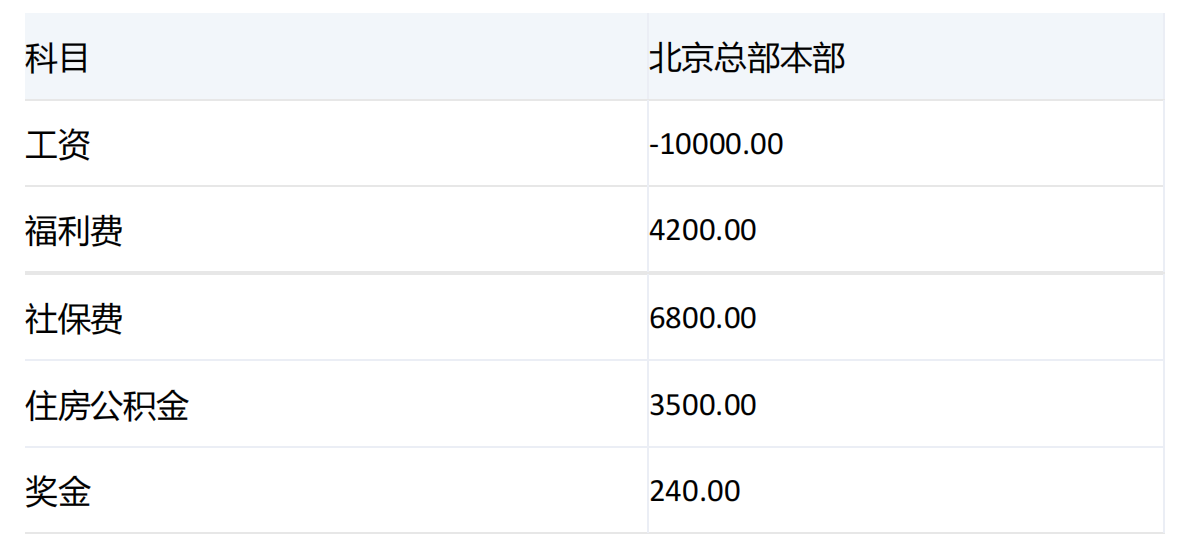
运行结果:
产品: 不分
场景: 累计预算
期间: 期间不分
版本: 年初编报01版本
-----------------------------------------------------------------------------------------------------------------
行上本来是两个维度(【科目】和【期间】)的成员交叉,使用extract函数提取出指定维度(【科目】)的成员
Filter
返回根据条件筛选指定集的结果集。
语法
FILTER(set, search_condition)
参数
set
返回集的有效多维表达式 (MDX)
search_condition
是逻辑表达式 ,作为筛选条件
示例
select
{Filter({[期间].[2023年].[2023年3季度].Children},[版本].&[50672]>0 and [版本].&[50672]<5000)} on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
科目: 研究开发费
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
筛选条件是大于0并且小于5000,所以筛选出的值为4800.00
Intersect
语法
INTERSECT(set, set [ , [ALL] ])
参数
set
返回集的有效多维表达式 (MDX)
All
有ALL参数则保留重复项
备注
返回两个输入集的交集
示例一
select
Intersect({[期间].&[50640],[期间].&[50640],[期间].&[50642]},{[期间].&[50640],[期间].&[50641],[期间].&[50640]}) on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
科目:研究开发费

-----------------------------------------------------------------------------------------------------------------
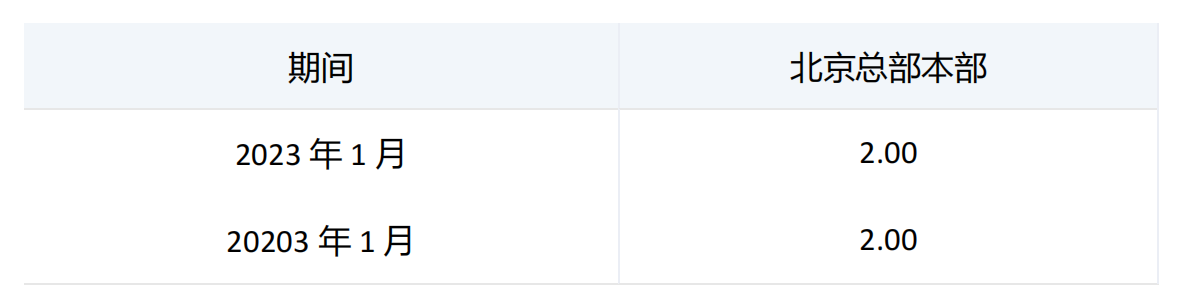
由于期间维度下第一个集合中2023年1月、2023年2月值分别为0、2、;第二个集合中2023年1月、2023年3月值分别为2、24,故在INTERSECT函数作用下,返回两个集合的交集,返回20203年3月值为2.
示例二
select
Intersect({[期间].&[50640],[期间].&[50640],[期间].&[50642]},{[期间].&[50640],[期间].&[50641],[期间].&[50640]},ALL) on rows,
{[组织].&[50582]} on columns
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
科目:研究开发费
-----------------------------------------------------------------------------------------------------------------
由于期间维度下第一个集合中2023年1月、2023年2月值分别为0、2、;第二个集合中2023年1月、2023年3月值分别为2、24,故在INTERSECT函数作用下,又添加了ALL,返回两个集合的交集并保留重复项,所有返回20203年1月值为2、2。(保留重复项)
Members
返回指定集合范围
语法
level.MEMBERS
hier_name.MEMBERS
参数
hier_name
返回指定集合范围
备注
返回指定级别或者层次结构上的所有成员
示例一
select
{[科目].&[50236]} on columns,
{[期间].[2023年].level.members}on rows
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[组织].&[50583])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
组织:研究中心

-----------------------------------------------------------------------------------------------------------------
由于期间维度下2021年、2022年、2023年分别为同层级成员,对应结果为100、100、1901.21,在MEMBERS函数下返回了期间维下2023年成员同层级的成员,分别为2021年、2022年、2023年,对应结果为100、100、1901.21.
示例二
select
{[科目].&[50236]} on columns,
{[期间].levels(2).members}on rows
from [模型一]
where ([场景].&[50685],[产品].&[50688],[版本].&[50672],[组织].&[50583])
运行结果:
产品: 不分
场景: 累计预算
版本: 年初编报01版本
组织:研究中心

-----------------------------------------------------------------------------------------------------------------
由于期间维度下2021年、2022年、2023年分别为同层级成员均为第2层级,2021年1、2、3、4季度,2022年1、2、3、4季度,2023年1、2、3、4季度均为第1层级成员,2021年1-12月、2022年1-12月、2023年1-12月均为第0层级成员,“[期间].levels(2).members”,取得是期间维下层级为2的同层级成员,分别为2021年、2022年、2023年,对应结果为100、100、1901.21.
Mtd
返回与给定成员相同级别的一组兄弟成员,从第一个兄弟成员开始,到给定成员结束,这受时间维度中的月份级别的限制。
语法
MTD( [member] )
参数
Member
是时间类型维度中的成员
备注
月份级别的名字必须是MONTHS(不区分大小写)
示例一
select
{[Organization].&[6]} on columns,
{MTD([Time].&[20101205])} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Account].&[60])
运行结果:
Account: Salaries
DepartmentGroup: Research and Development
Scenario: Actual
-----------------------------------------------------------------------------------------------------------------
指定成员的月份为2010年12月5日,月份级别的祖先是2010年12月,第一个和指定成员同级的后代为20101201,
因为从20101201到指定成员20101205共五个成员,所以结果有5行(显示的名字是成员在当前月的编号)。
示例二
with member [Account].[x] as Sum(MTD([Time].currentmember),[Account].&[60])
select
{[Organization].&[6]} on columns,
{[Account].[x]} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Time].&[20101229])
运行结果:
DepartmentGroup: Research and Development
Scenario: Actual
Time: 29

-----------------------------------------------------------------------------------------------------------------
维度Time的当前成员为20101229,所以代入mtd函数后返回从20101201至20101229共29个成员,所以结果值为对应的29个单元格的值的和。
Order
排列指定集合中的成员,可以选择保留或打乱原有的层次结构。
语法
Order(set, numeric_value [ , { ASC | DESC | BASC | BDESC } ])
参数
set
返回集的有效多维表达式 (MDX),按集合中位置靠后的维度成员进行排序。
numeric_value
返回集的排序依据,优先级高于set。
备注
Order 有两种变化形式:按层次结构排列(ASC 或 DESC)和不按层次结构排列(BASC 或 BDESC,其中 B 代表打乱原有层次结构)。按层次结构排列的排序首先按成员在层次结构中的位置对其进行排序,然后再对每个级别进行排序。而不按层次结构排列的排序在对集合中的成员排序时不考虑层次结构。如果没有明确说明,则根据默认设置使用 ASC。
示例一
select
Order({[科目].&[50236],[科目].&[50240]}*{[期间].[2023年].[2023年3季度].Children},[版本].&[50672],desc) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 北京总部本部
-----------------------------------------------------------------------------------------------------------------
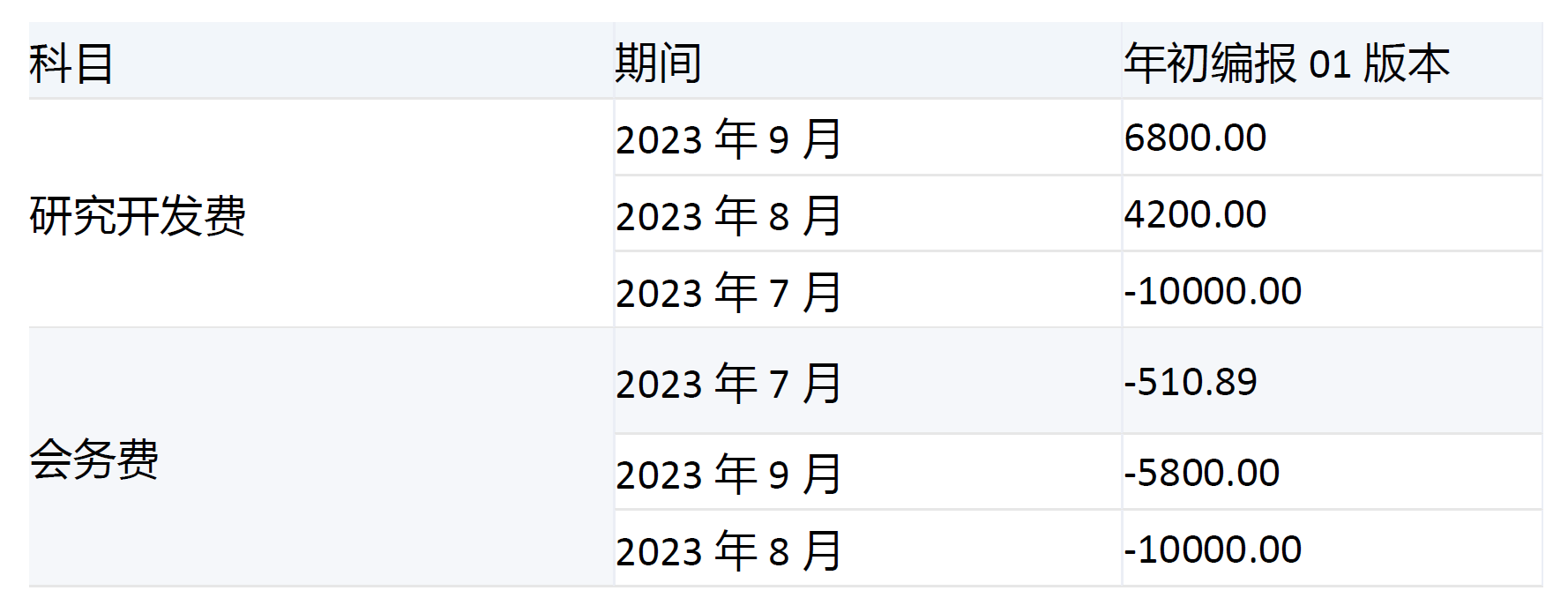
由于期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,在Order函数的集合中,期间维度位置靠后,所以会对[研究开发费]的[2023年3季度]的子项的值进行降序排列,顺序为6800、4200、-10000,对应返回的期间顺序为[2023年9月]、[2023年8月]、[2023年7月];
由于期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[会务费]对应的值分别为-510.89、-10000、-5800,在Order函数的集合中,期间维度位置靠后,所以会对[会务费]的[2023年3季度]的子项的值进行降序排列,顺序为-510.89、-5800、-10000,对应返回的期间顺序为[2023年7月]、[2023年9月]、[2023年8月]。
示例二
select
Order({[期间].[2023年].[2023年3季度].Children}*{[科目].&[50236],[科目].&[50240]},[版本].&[50672],bdesc) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688])
运行结果:
产品: 不分
场景: 累计预算
组织: 北京总部本部
-----------------------------------------------------------------------------------------------------------------
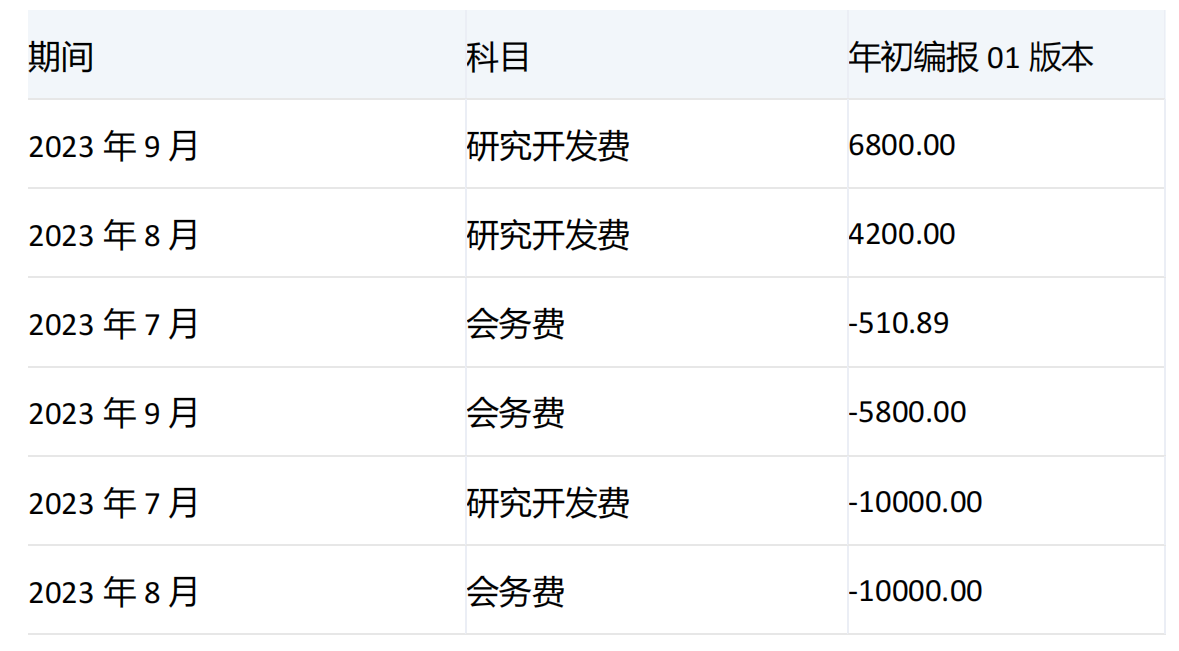
由于期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,[会务费]对应的值分别为-510.89、-10000、-5800,在Order函数中使用了bdesc参数,来打破集合中维度成员的层次结构,对数据进行降序排列,所以顺序为6800、4200、-510.89、-5800、-10000、-10000,对应返回的维度组合顺序为[2023年9月]的[研究开发费]、[2023年8月]的[研究开发费]、[2023年7月]的[会务费]、[2023年9月]的[会务费]、[2023年7月]的[研究开发费]、[2023年8月]的[会务费]。
PeriodsToDate
返回与给定成员相同级别的一组同级成员,从第一个同级成员开始,以给定成员结束。
语法
PERIODSTODATE( [level [, member] ] )
参数
level
只有level参数,返回指定成员同一级别从开始到指定成员。
Member
(可选)是时间类型维度中的成员
示例一
select
{PeriodsToDate([期间].[LEVEL0],[期间].[2023年].[2023年3季度].[2023年9月])} on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50253])
运行结果:
产品: 不分
场景: 累计预算
科目: 物业外包
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
既指定了Member又指定了level,并且他们在同一级别,返回成员本身。
示例二
select
{PeriodsToDate([期间].[LEVEL1],[期间].[2023年].[2023年3季度].[2023年9月])} on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50253])
运行结果:
产品: 不分
场景: 累计预算
科目: 物业外包
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
既指定了Member[2023年9月],它的级别是0,又指定了level级别为1,并且Member的级别小于level级别,返回[2023年3季度]第一个同级别子项[2023年7月直到成员本身。
示例三
with member [科目].[x] as Sum(PeriodsToDate([期间].[LEVEL1]),[科目].&[50253])
select
{[科目].[x]} on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[期间].[2023年].[2023年3季度].[2023年9月])
运行结果:
产品: 不分
场景: 累计预算
期间: 2023年9月
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
只指定了level级别为1,示例二指定的Member[2023年9月]放在where后面,它的级别是0并且Member的级别小于level级别,返回[2023年3季度]第一个同级别子项[2023年7月直到成员本身,的累加。
Qtd
返回与给定成员来自同一级别的兄弟成员集合,从第一个兄弟成员开始,以给定成员结束,这受Time维度中的季度级别的限制。
语法
QTD( [member] )
参数
Member
是时间类型维度中的成员
备注
季度级别的名字必须为QUARTER(不区分大小写)
示例一
select
{[Organization].&[6]} on columns,
{QTD([Time].&[20130106])} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Account].&[60])
运行结果:
Account: Salaries
DepartmentGroup: Research and Development
Scenario: Actual
-----------------------------------------------------------------------------------------------------------------
指定成员的月份为2013年1月6日,季度级别的祖先是2013年1季度,第一个和指定成员同级的后代为20130101,
因为从20130101到指定成员2010106共六个成员,所以结果有6行(显示的名字是成员在当前月的编号)
示例二
with member [Account].[x] as Sum(Qtd([Time].currentmember),[Account].&[60])
select
{[Organization].&[6]} on columns,
{[Account].[x]} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Time].[2013].[1].[February])
运行结果:
DepartmentGroup: Research and Development
Scenario: Actual
Time: February

-----------------------------------------------------------------------------------------------------------------
维度Time的当前成员为2013年1季度2月,所以代入qtd函数后返回从2013年1季度1月至2013年1季度2月共2个成员,所以结果值为对应的2个单元格的值的和。
TopCount
返回指定集合中指定数目具有较大值的元组组成的集合。
语法
TOPCOUNT(set, index [, numeric_value] )
参数
set
返回集的有效多维表达式 (MDX)。
index
指定了返回tuple的数目(不超过index的值)
numeric_value
(可选)指定了numeric_value则返回的同级成员会据此排序(降序)
示例一
select
TopCount({[期间].[2023年].[2023年3季度].Children},2) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
科目: 研究开发费
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
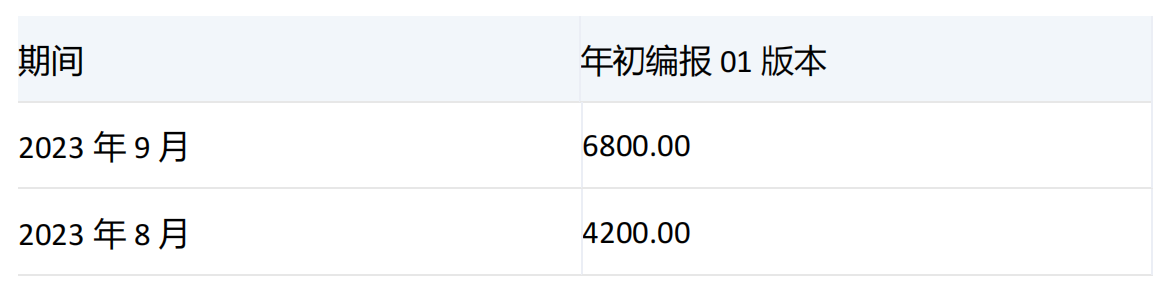
期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,由于指定了index,所以只返回前两个月[2023年7月]和[2023年8月]。
示例二
select
TopCount({[期间].[2023年].[2023年3季度].Children},2,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
科目: 研究开发费
组织: 北京总部本部
-----------------------------------------------------------------------------------------------------------------
期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,由于指定了numeric_value参数,所以[2023年3季度]的子项要按值的大小进行降序排列,结果为6800,4200,-10000
由于index的限制,所以只返回排序后的前两个月[2023年9月]和[2023年8月]。
TopPercent
将指定维度成员范围内数据降序排列,从最大值开始累加,当累加大于或等于全部返回值总和的指定百分比后,返回集合。
语法
TOPPERCENT(set, percentage , numeric_value)
参数
set
返回集的有效多维表达式 (MDX)。
percentage
指定了返回元组和在总值中的占比。
numeric_value
返回的同级成员会据此排序(降序)。
备注
百分比不需要输入%
示例一
select
TopPercent({[期间].[2023年].[2023年3季度].Children},10,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
科目: 研究开发费
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,按降序排列结果为6800、4200、-10000,指定百分比为10,也就是6800、4200、-10000先求和再乘以10%为1000,当取到6800时,刚好大于1000,满足大于等于10000的条件,所以只需要返回[2023年9月]。
TopSum
将指定维度成员范围内数据降序排列,从最大值开始累加,当累加大于或等于给定的值后,返回集合。
语法
TOMSUM(set, value, numeric_value)
参数
set
返回集的有效多维表达式 (MDX)。
Value
指定了返回的元组需要满足的条件。
numeric_value
返回的同级成员会据此排序(降序)。
示例
select
TopSum({[期间].[2023年].[2023年3季度].Children},1000,[版本].&[50672]) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50236])
运行结果:
产品: 不分
场景: 累计预算
科目: 研究开发费
组织: 北京总部本部

-----------------------------------------------------------------------------------------------------------------
由于期间维度[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[研究开发费]值分别为-10000、4200、6800,降序排列结果为6800、4200、-10000,指定值为1000,当取到6800时,刚好大于1000,满足大于等于1000的条件,所以返回[2023年9月]。
Union
默认返回两个维度组合的并集,并进行去重,若添加参数ALL,则可保留
并集中的重复项。
语法
UNION(set,set… [, [ALL] ])
参数
set
返回集的有效多维表达式 (MDX)。
ALL
不加ALL参数,剔除所有的重复项,有ALL参数,保留所有项。
示例一
select
Union({[期间].[2023年].[2023年3季度].Children},{[期间].[2023年].[2023年3季度].[2023年7月]}) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50254])
运行结果:
产品: 不分
场景: 累计预算
科目: 保洁费
组织: 北京总部本部
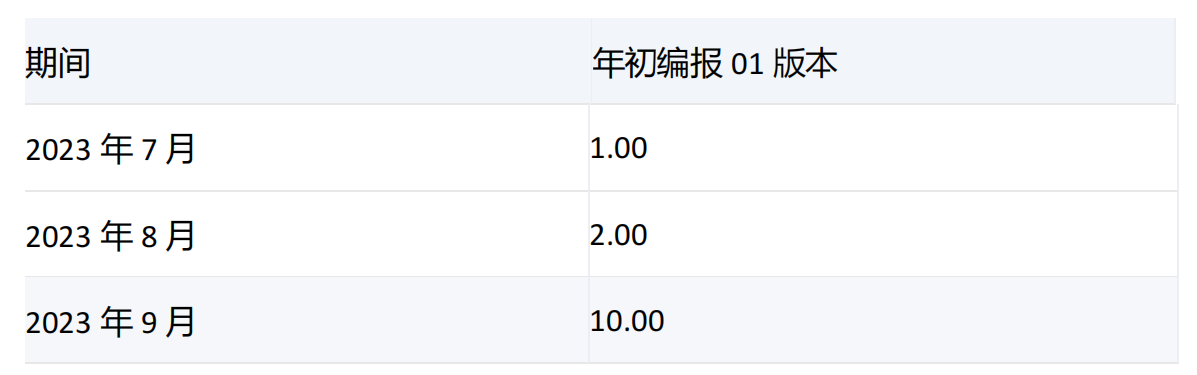
-----------------------------------------------------------------------------------------------------------------
由于[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[保洁费]的值分别为1、2、10,集合1和集合2中[2023年7月]重复,没有参数ALL,默认去重,所以返回[2023年7月]、[2023年8月]、[2023年9月]。
示例二
select
Union({[期间].[2023年].[2023年3季度].Children},{[期间].[2023年].[2023年3季度].[2023年7月]},ALL) on rows,
{[版本].&[50672]} on columns
from [模型一]
where ([组织].&[50582],[场景].&[50685],[产品].&[50688],[科目].&[50254])
运行结果:
产品: 不分
场景: 累计预算
科目: 保洁费
组织: 北京总部本部
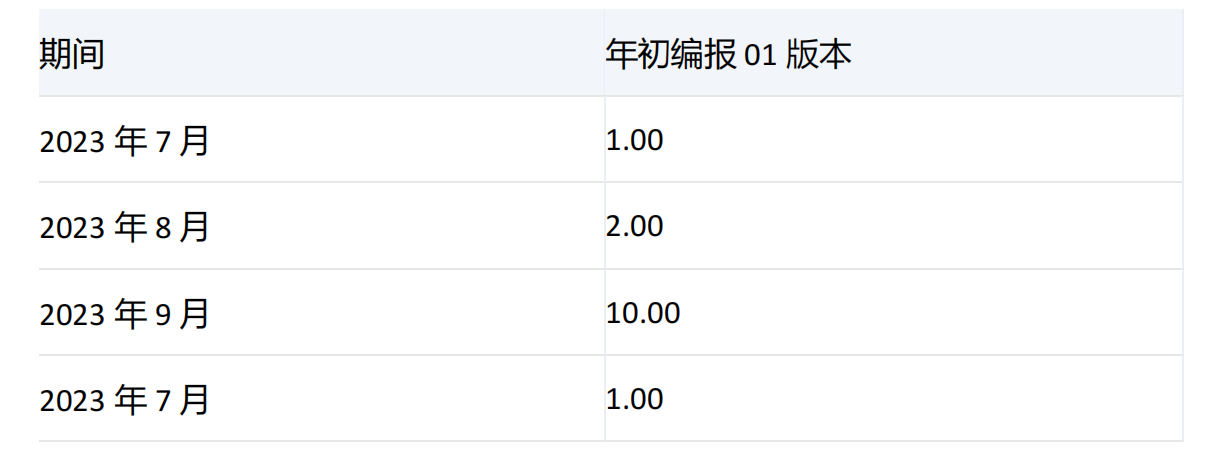
-----------------------------------------------------------------------------------------------------------------
由于[2023年3季度]的子项[2023年7月]、[2023年8月]、[2023年9月]的[保洁费]的值分别为1、2、10,集合1和集合2中[2023年7月]重复,已设置参数ALL,保留重复项,所以返回[2023年7月]、[2023年8月]、[2023年9月]、[2023年7月]。
Wtd
返回与给定成员相同级别的兄弟成员集合,从第一个兄弟成员开始,到给定成员结束,这受时间维度中的周级别的限制。
语法
WTD( [member] )
参数
Member
是时间类型维度中的成员
备注
周级别的名字必须为WEEKS(不区分大小写)
示例一
select
{[Organization].&[6]} on columns,
{WTD([Time].[2013].[9].[Thursday])} on rows
from [Week AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Account].&[60])
运行结果:
Account: Salaries
DepartmentGroup: Research and Development
Scenario: Actual
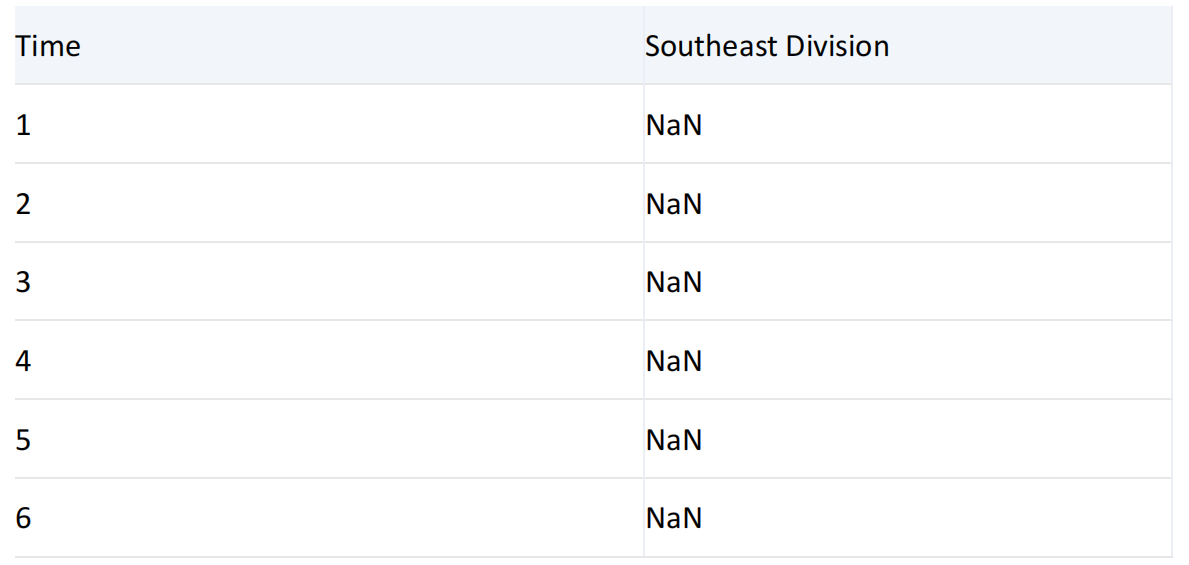
-----------------------------------------------------------------------------------------------------------------
指定成员的月份为2013年第9周的Thursday,所以行上为Sunday至Thursday(第9周)
示例二
with member [Account].[x] as Sum(WTD([Time].currentmember),[Account].&[60])
select
{[Organization].&[6]} on columns,
{[Account].[x]} on rows
from [Week AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Time].[2013].[9].[Thursday])
运行结果:
DepartmentGroup: Research and Development
Scenario: Actual
Time: Thursday

-----------------------------------------------------------------------------------------------------------------
维度Time的当前成员为2013年第9周的Thursday,所以代入wtd函数后返回从2013年第9周的Sunday至2013年第9周的Thursday共5个成员(如示例1所示),所以结果值为对应的5个单元格的值的和。
Ytd
返回与给定成员相同级别的一组兄弟成员,从第一个兄弟成员开始,到给定成员结束,这受时间维度中的Year级别的限制。
语法
YTD([member])
参数
Member
是时间类型维度中的成员
备注
季度级别的名字必须为YEAR(不区分大小写)
示例一
select
{[Organization].&[6]} on columns,
{YTD([Time].&[20130106])} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Account].&[60])
运行结果:
Account: Salaries
DepartmentGroup: Research and Development
Scenario: Actual

-----------------------------------------------------------------------------------------------------------------
指定成员的月份为2013年1月6日,年级别的祖先是2013年,第一个和指定成员同级的后代为20130101,
因为从20130101到指定成员2010106共六个成员,所以结果有6行。
示例二
with member [Account].[x] as Sum(Ytd([Time].currentmember),[Account].&[60])
select
{[Organization].&[6]} on columns,
{[Account].[x]} on rows
from [AdventureWorks]
where ([DepartmentGroup].&[6],[Scenario].&[1],[Time].[2013].[3])
运行结果:
DepartmentGroup: Research and Development
Scenario: Actual
Time: 3

-----------------------------------------------------------------------------------------------------------------
维度Time的当前成员为2013年3季度,所以代入qtd函数后返回从2013年1季度至2013年3季度共3个成员,所以结果值为对应的3个单元格的值的和。
版权声明:
1、本文档所有内容文字资料, 版权均属北京智达方通科技有限公司所有,任何企业、媒体、网站或个人未经本公司协议授权不得转载、链接、转发或以其他方式复制、发布/发表。已经本公司协议授权的媒体、网站,在下载使用时必须注明来源,违者本公司将依法追究责任。
2、对不遵守本声明或其他违法、恶意使用本公司内容者,本公司保留追究其法律责任的权利。

 智达方通官方微信
智达方通官方微信




 京公网安备 11010502040655号
京公网安备 11010502040655号